再构想
基于改进YOLOv5的刨花实例分割
目标
- 构建检测速度快,识别准确率高的神经网络
- 用于复杂环境下定向刨花板铺装过程中刨花定向角度的检测
- 降低Yolov5的权重文件大小,使其便于嵌入式或移动端设备的开发
思路
- 大片刨花分割数据集的构建,由于公开的刨花分割数据集较少,构建一个新的大片刨花的数据集。
- 提供了与现有主流的实例分割网络、目标检测网络的对比
- 基于YOLOv5的刨花检测与分割。使用多种任务模型来解决复杂环境下刨花分割图像的问题,在保证高精度的同时进行检测和分割。同时利用Ghost模块或Shuflenetv2模块进一步优化模型,减少模型的参数量。
- 基于分割后的图像对刨花进行定向角度的测量
一些主流神经网络算法及YOLOv5改进思路
- YOLOv3-ting
- YOLOv8
- YOLOv5s-segment C3
- YOLOv5s-segment C3Ghost(+Hardswish)
- YOLOv5s-segment Shufflenet(+Hardswish)
YOLOv5主干网络概述
YOLOv5算法是单阶段目标识别算法(one stage),即基于整个图片/视频进行预测,一次性给出所有检测结果。
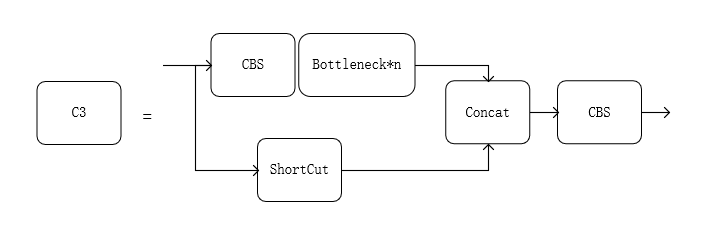
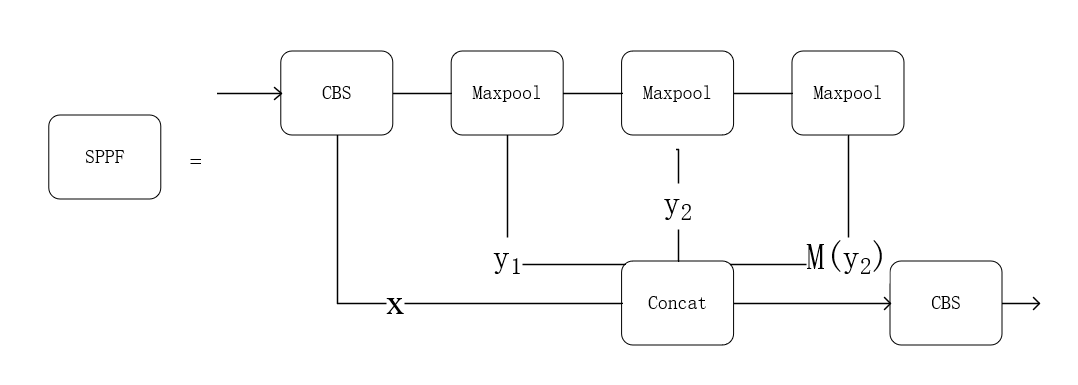
网络结构主要由输入端、Backbone、 Neck、Head 四部分构成,输入端使用 Mosaic 数据增强、 自适应初始锚框计算、图片缩放等对图像进行预处理。Backbone主要由CBS、Bottleneck、C3、以及SPPF组成。
CBS模块主要由Conv+BatchNorm+SiLU组成,YOLOv5中的Conv模块通过autopad函数实现自适应padding的效果,并且控制是否对特征图进行激活操作,SiLU表示使用Sigmoid进行激活。

Bottleneck模块利用两个 Conv 模块将通道数先减小再扩大对齐, 以此提取特征信息,并使用 ShortCut 控制是否进行残差连接。它主要是被封装在C3模块中进行特征提取。
YOLOv5在backbone中shortcut=True,neck中shortcut=False。
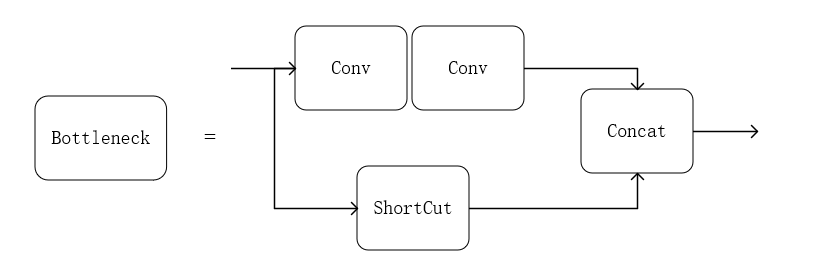
C3模块输入特征图会通过两个分支,第一个分支先经过一个CBS模块,之后通过堆叠的Bottleneck 模块对特征进行学习;另一分支作为残差连接,仅通过 一个CBS模块。两分支最终按通道进行拼接后,再通过一个CBS模块进行输出。
SSPF模块将经过CBS模块的x、一次池化后的y1、两次池化后的y2和3次池化后的self.m(y2)先进行拼接,然后再传入CBS模块进行提取特征。此处多次的池化并未对特征图的尺寸进行修改,它的主要作用是对特征进行提取并融合,在融合的过程中作者多次运用最大池化,尽可能多的去提取高层次的语义特征。
改进后的YOLOv5结构
Ghost模块
ShuffleNetv2