YOLOv5训练结果
yoloV5_results
训练完成后会生成一个exp的文件夹
weights
best.pt和last.pt,最好的和最后一次的,做detect是用best
confusion——matrix.png
混淆矩阵
event.out
未知
F1_curve.png
置信度和F1曲线的关系,x轴为置信度,y轴为F1得分
hyp.yaml
训练相关超参数
labels.jpg
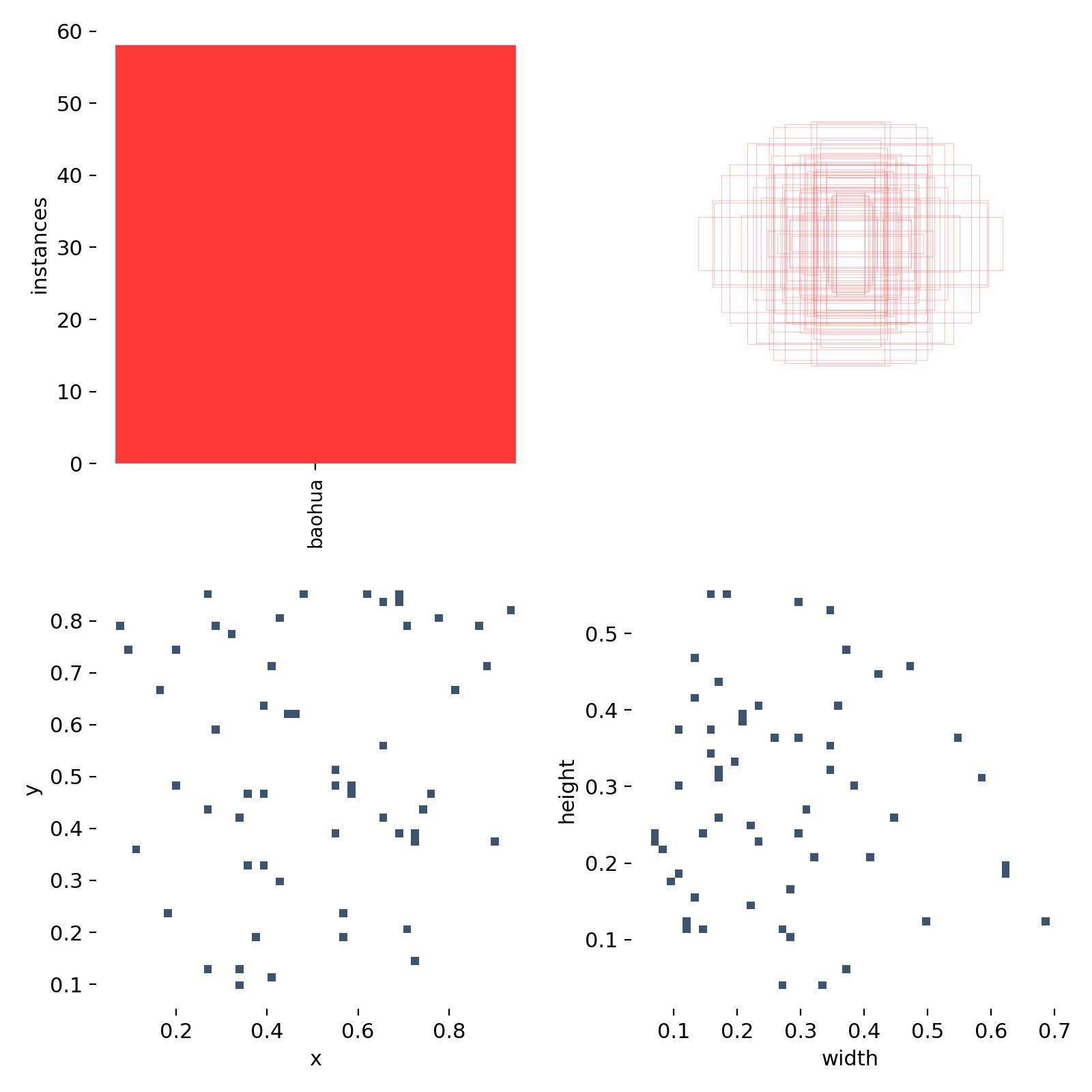
左一:每个类别的数据量 (只有一个类别
右一:labels的 bounding_box
左二:labels的中心点坐标
右二:labels的矩阵宽高
labels_correlogram.jpg
比较复杂,看不懂,别人的解释如下:
labels的中心点x,y和矩阵宽高w,h
顶端对角线上:各自的分布直方图
其余位置:相互之间的分布情况
opt.yaml
最优参数
P_curve.png
准确率与置信度的关系
PR_curve.png
PR曲线中的P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系,一般情况下,将recall设置为横坐标,precision设置为纵坐标。PR曲线下围成的面积即AP,所有类别AP平均值即Map. 如果PR图的其中的一个曲线A完全包住另一个学习器的曲线B,则可断言A的性能优于B,当A和B发生交叉时,可以根据曲线下方的面积大小来进行比较。一般训练结果主要观察精度和召回率波动情况(波动不是很大则训练效果较好) Precision和Recall往往是一对矛盾的性能度量指标; 提高Precision == 提高二分类器预测正例门槛 == 使得二分类器预测的正例尽可能是真实正例; 提高Recall == 降低二分类器预测正例门槛 == 使得二分类器尽可能将真实的正例挑选
R_curve.png
召回率和置信度之间的关系
results.csv
每一次迭代对应的
train/box_loss, train/obj_loss, train/cls_loss metrics/precision,metrics/recall,metrics/mAP_0.5,metrics/mAP_0.5:0.95 val/box_loss, val/obj_loss,val/cls_loss,x/lr0, x/lr1, x/lr2
result.png
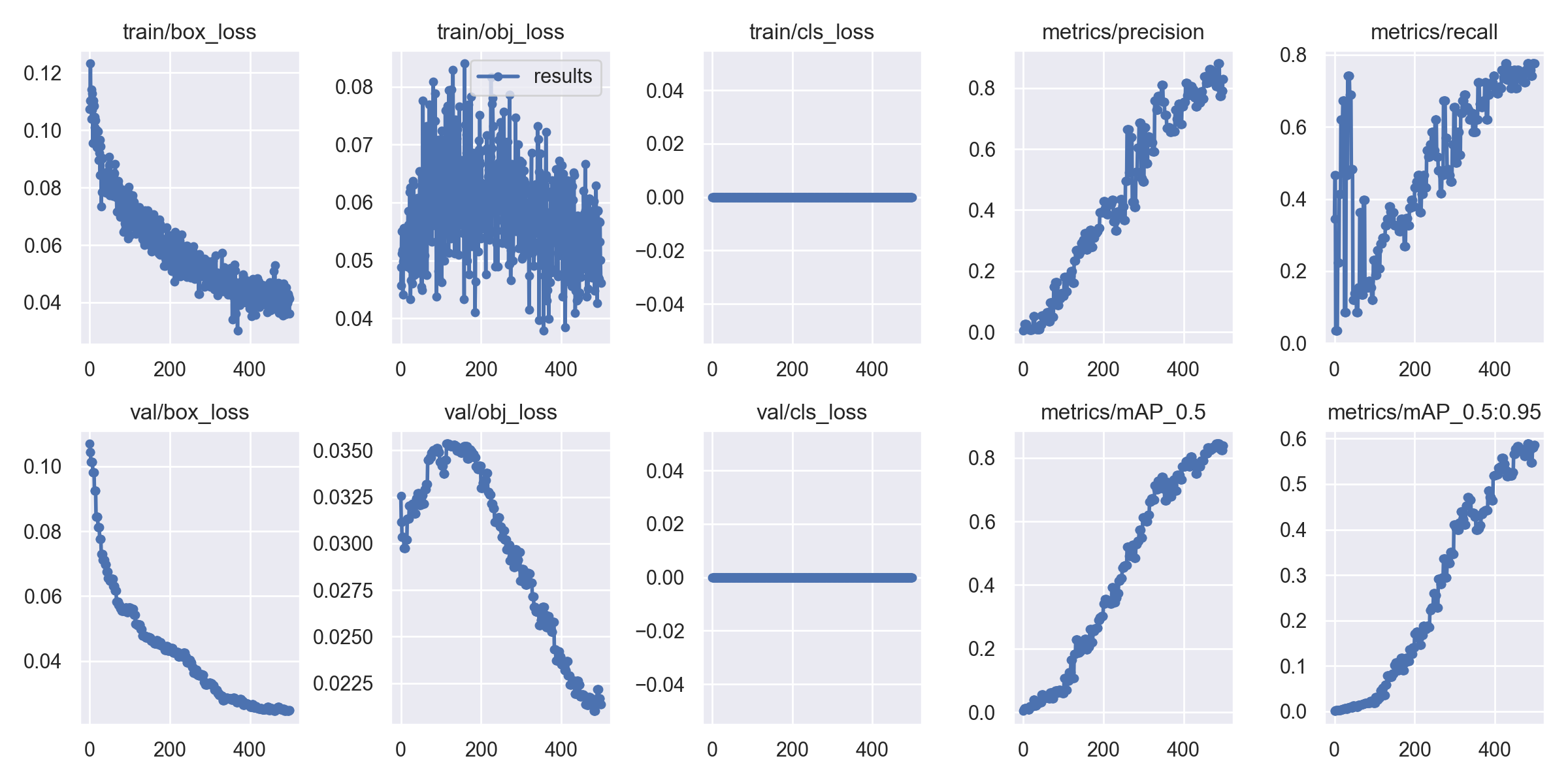
Box_loss:YOLO V5使用 GIOU Loss作为bounding box的损失,Box推测为GIoU损失函数均值,越小方框越准; Objectness_loss:推测为目标检测loss均值,越小目标检测越准; Classification_loss:推测为分类loss均值,越小分类越准; Precision:精度(找对的正类/所有找到的正类); Recall:真实为positive的准确率,即正样本有多少被找出来了(召回了多少).Recall从真实结果角度出发,描述了测试集中的真实正例有多少被二分类器挑选了出来,即真实的正例有多少被该二分类器召回。 val Box_loss: 验证集bounding box损失; val Objectness_loss:验证集目标检测loss均值; val classification_loss:验证集分类loss均值; mAP@.5:.95(mAP@[.5:.95]): 表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。mAP@.5:表示阈值大于0.5的平均mAP。然后观察mAP@0.5 & mAP@0.5:0.95 评价训练结果。mAP是用Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值,@0.5:0.95表示阈值取0.5:0.05:0.95后取均值
参考文章:https://blog.csdn.net/qq_45305490/article/details/125219937 https://blog.csdn.net/XiaoGShou/article/details/118274900